上海羊羽卓进出口贸易有限公司
上海羊羽卓进出口贸易有限公司从“会说”到“会做”:AI Agent正在改变人机交互方式
如果说RAG让大模型(Large Language Model,LLM)学会了“开卷考试”,那么AI Agent(Artificial Intelligence Agent,人工智能智能体)则赋予了LLM“手和脚”,使其能够思考、规划并与真实世界互动-61。2024年,大模型从“会说”走向“会做”,AI Agent应运而生,将认知能力转化为实际行动-11。2025年被誉为“智能体元年”,AI Agent从通用平台技术转向垂直行业应用,在医疗、金融、工业制造等知识密集型领域创造明确的业务价值-1。然而许多学习者在接触这一技术时面临共同的痛点——会用LangChain调用API,但搞不清Agent与普通LLM的本质区别;看过几个Demo,却说不明白ReAct框架的运作原理;面试时遇到“Agent和Workflow有什么区别”这类问题,只能支支吾吾-。本文将从痛点切入→核心概念→关联解析→代码实战→底层原理→面试考点六个层面,系统拆解AI Agent技术体系,让你看完就能懂原理、会写代码、能答面试。

一、痛点切入:为什么有了大模型还不够?
大模型的能力固然强大——GPT-4o、Claude 3.5、DeepSeek等模型在语言理解和生成上已接近人类水平。但在真实的软件系统中,单一模型并不能直接解决复杂工程任务-7。
看一个典型场景:用户说“帮我查今天北京的天气,再根据天气预订一家评分最高的中餐厅”。
用传统方法(纯LLM调用):
import openai response = openai.ChatCompletion.create( model="gpt-4", messages=[{"role": "user", "content": "帮我查今天北京的天气,然后预订一家评分最高的中餐厅"}] ) print(response.choices[0].message.content) 输出: "抱歉,我无法获取实时天气信息,也无法帮你预订餐厅。建议你打开天气App查看,然后用大众点评预订。"
这段代码的问题在哪?大模型本身没有获取实时数据的能力,更没有执行预订操作的权限。它只能给出建议,却无法真正“做事”。
传统方式的四大痛点:
无法获取实时数据:LLM的训练数据有截止日期,不知道今天的天气
无法执行具体操作:LLM只会生成文本,不会调用API、不会发邮件、不会下单
缺乏自主规划能力:面对多步骤任务(查天气→筛选餐厅→预订→发确认),LLM没有“分解目标”的能力
无法记忆上下文:简单对话中尚可维持,但长周期任务极易丢失上下文
这些痛点催生了AI Agent的诞生——它不是对LLM的替代,而是对LLM能力的“工程化放大”-7。
二、核心概念:AI Agent到底是什么?
定义
AI Agent(人工智能智能体),全称Artificial Intelligence Agent,是指以大型语言模型为决策核心,具备感知、规划、记忆和行动能力的自主系统,能够理解复杂目标、动态拆解任务、调用外部工具,并在与环境的交互中持续优化行为以达成目标-7。
一句话概括:Agent = LLM(大脑) + 记忆 + 规划 + 工具 + 行动能力-35。
拆解核心关键词
感知(Perception) :Agent的眼睛和耳朵。不仅接收文本输入,还能处理图像、结构化数据、音频乃至物理传感器数据,获取环境状态和用户意图-1。
规划(Planning) :Agent的决策中枢。面对复杂目标(如“帮我规划一趟去北京的旅行”),将其拆解为可执行的子任务序列(查机票→订酒店→规划行程→发确认邮件)-7。
记忆(Memory) :Agent的经验积累。短期记忆维持当前对话的连贯性,长期记忆将用户偏好、历史决策存入外部数据库(如向量数据库),下次遇到相似任务时可参考-61。
行动(Action) :Agent的手和脚。通过调用工具(Tool)或函数(Function)执行具体操作,如调用天气API、发送邮件、操作数据库-7。
生活化类比
把LLM比作一位知识渊博的大学教授——他懂得很多理论,但只会回答问题,不会实际操作。AI Agent则是这位教授配备了一位全能助手:助手会查实时数据、会操作各种工具、会规划行程,教授负责思考和决策,助手负责动手执行。教授(LLM)加上助手(感知+规划+记忆+行动),就是一个完整的Agent。
三、关联概念:LLM、Workflow与Agent的本质区别
在日常讨论中,LLM、Workflow(工作流)和Agent经常被混用。理解三者的区别,是面试中高频考察的考点。
1. LLM(大语言模型)
定义:Large Language Model,基于海量文本训练的概率生成模型。
能力边界:输入文本→输出文本,是一个封闭循环。GPT-4的token限制导致无法处理超长文档,也无法获取实时数据-。
类比:一个只读过书、从未出过门的学者。
2. Workflow(工作流)
定义:预设的确定性任务执行路径,通常通过代码或配置文件明确定义每一步做什么。
能力边界:效率高、可预测,但缺乏对复杂语义和不确定环境的适应能力-7。遇到预设之外的情况就会失败。
类比:工厂里的流水线——每个工位做什么是定死的,产品规格变了就要重新配置。
3. Agent(智能体)
定义:以LLM为核心决策单元,叠加规划、执行和状态管理能力的系统形态-7。
能力边界:能够动态生成解决方案、感知上下文、调用工具、持续学习和调整。
类比:一个有经验的管家——能理解你的模糊指令,会根据情况灵活调整方案。
三者关系一句话概括
LLM提供认知能力,Workflow提供确定性路径,Agent在此基础上加入了自主决策和动态适应能力——Agent是“思考者+行动者”的合体,而LLM只是“大脑”,Workflow只是“流水线”-7。
对比表
| 维度 | LLM | Workflow | Agent |
|---|---|---|---|
| 决策方式 | 概率生成 | 预设规则 | 动态规划 |
| 工具调用 | 不支持 | 代码硬编码 | 自主选择 |
| 环境适应 | 无 | 固定 | 自适应 |
| 记忆能力 | 对话窗口 | 不适用 | 短期+长期 |
| 典型输出 | 文本回答 | 固定动作 | 任务完成 |
四、概念关系梳理:Agent的四大核心模块如何协同工作?
一个完整的Agent系统由四个核心模块协同运作,形成“感知→规划→行动→记忆”的认知闭环-1。
┌─────────────────────────────────────────────────────────────┐ │ AI Agent 架构 │ ├─────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │ │ 感知模块 │────▶│ 规划模块 │────▶│ 行动模块 │ │ │ │(Perception) │(Planning) │(Action) │ │ │ └─────────┘ └─────────┘ └─────────┘ │ │ ▲ │ │ │ │ │ ▼ │ │ │ │ ┌─────────┐ │ │ │ └─────────│ 记忆模块 │◀──────────┘ │ │ │ (Memory) │ │ │ └─────────┘ │ │ │ └─────────────────────────────────────────────────────────────┘
协同流程详解:
感知模块接收用户输入和环境信息,结构化处理后传递给规划模块
规划模块以LLM为大脑,拆解目标、制定行动序列,向行动模块下达指令
行动模块调用具体工具(API、数据库、代码执行器等)执行操作
记忆模块记录每一步的上下文和执行结果,供后续决策参考,同时将执行结果反馈给感知模块,形成闭环-1
五、底层原理:ReAct框架是如何驱动Agent工作的?
理解了Agent的模块构成,下一步需要知道这些模块是如何协同决策的——这正是面试中的高频考点。当前主流的Agent工作模式是ReAct(Reasoning + Acting) 框架,由Google Research在2022年提出。
ReAct的核心原理
ReAct是一种“思考-行动”交替循环的模式。在每一轮交互中,Agent会依次经历:思考(Thought) → 行动(Action) → 观察(Observation) ,然后根据观察结果进入下一轮思考,直到任务完成-61。
伪代码展示核心逻辑
Agent 核心 ReAct 循环 messages = [] 存储对话上下文 available_tools = [weather_api, search_api, book_restaurant] 可用工具列表 while True: 1. 思考:将上下文和工具列表交给 LLM,获取下一步行动计划 thought = llm.reason(messages, available_tools) 2. 决策:判断是否调用工具 if thought.has_tool_calls(): 3. 行动:调用指定工具,传入参数 tool_result = call_tool(thought.tool_name, thought.params) 4. 观察:将执行结果作为新的上下文,继续循环 messages.append(Observation(tool_result)) continue else: 无工具调用,返回最终答案 return thought.text
实际运行示例
以“帮我查今天北京的天气”为例,ReAct循环的执行过程如下:
| 步骤 | 类型 | 内容 |
|---|---|---|
| 第1轮 | 思考 | 用户想知道北京的天气,我应该调用 weather_api 工具,参数为城市名 |
| 第1轮 | 行动 | weather_api(city="北京") |
| 第1轮 | 观察 | “北京今天晴,气温25°C” |
| 第2轮 | 思考 | 已成功获取天气信息,可以给用户最终答案了 |
| 第2轮 | 最终回答 | “北京今天晴,气温25°C” |
这就是ReAct的核心价值:通过交替的思考与行动,LLM能够自主完成需要多步操作的复杂任务,并且每一步决策都基于上一步的实际执行结果,大幅减少了“幻觉”(Hallucination)问题-61-42。
六、代码实战:用LangChain实现一个可调用工具的Agent
理论讲完了,我们用代码来落地。以下代码基于LangChain框架,构建一个能够调用天气查询API和计算器的Agent。
环境准备
pip install langchain langchain-openai python-dotenv完整代码示例
import os from dotenv import load_dotenv from langchain_openai import ChatOpenAI from langchain.agents import create_tool_calling_agent, AgentExecutor from langchain.tools import tool from langchain_core.prompts import ChatPromptTemplate load_dotenv() 加载 .env 中的 OPENAI_API_KEY 1. 定义工具(Agent的“手和脚”) @tool def get_current_weather(city: str) -> str: """查询指定城市的实时天气(模拟实现)""" 实际应用中这里应调用真实天气API weather_data = { "北京": "晴,25°C,湿度40%", "上海": "多云,22°C,湿度65%", "深圳": "阵雨,28°C,湿度80%" } return weather_data.get(city, f"暂时无法获取{city}的天气信息") @tool def calculate(expression: str) -> str: """计算数学表达式,例如 '3 8 + 5'""" try: result = eval(expression) return f"{expression} = {result}" except Exception as e: return f"计算出错: {e}" 2. 初始化 LLM(Agent的“大脑”) llm = ChatOpenAI(model="gpt-4", temperature=0) 3. 注册工具到 Agent tools = [get_current_weather, calculate] 4. 定义提示模板 prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个智能助手,可以调用工具来帮助用户完成任务。"), ("human", "{input}"), ("placeholder", "{agent_scratchpad}") ]) 5. 创建 Agent 和执行器 agent = create_tool_calling_agent(llm, tools, prompt) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) 6. 运行 Agent if __name__ == "__main__": 示例1:天气查询 result = agent_executor.invoke({ "input": "今天北京的天气怎么样?适合出门吗?" }) print(f"Agent回答: {result['output']}") 示例2:数学计算 result = agent_executor.invoke({ "input": "帮我计算 (8 + 2) 3 的结果" }) print(f"Agent回答: {result['output']}")
代码执行流程解析:
用户输入“今天北京的天气怎么样?”→ Agent的“大脑”(LLM)接收输入
LLM判断需要调用
get_current_weather工具,生成工具调用指令AgentExecutor执行该工具,获取返回值“晴,25°C,湿度40%”
观察结果返回给LLM,LLM生成最终回答“北京今天晴,25°C,适合出门”
新旧实现方式对比:
传统纯LLM:只能回答“抱歉,我无法获取实时天气”
Agent方式:自动判断需要调用工具→执行→返回真实数据→给出建议
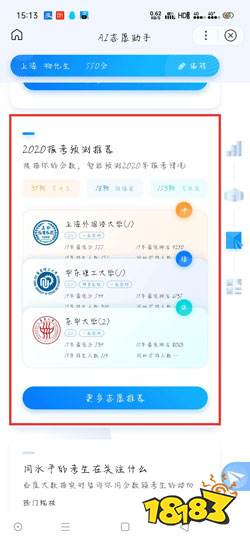
应用场景延伸:AI志愿填报助手
基于上述Agent框架,可以快速构建一个高考志愿填报助手。以百度AI志愿助手为例,该工具在2025年升级后接入了文心大模型和DeepSeek-R1等多个大模型,支持自然语言对话,能提供“冲稳保”志愿推荐,并聚合往年录取数据、院校录取概率等信息-50。2024年6月25日,已有超过1000万用户使用该工具-50。
核心实现逻辑可参考以下伪代码:
@tool def get_admission_probability(score: int, school: str, major: str) -> dict: """基于历史录取数据和考生分数,计算某校某专业的录取概率""" 查询历年分数线数据库 + 分析招生计划变动 return {"probability": "85%", "suggestion": "建议作为冲刺志愿"} @tool def recommend_schools(score: int, province: str, preference: str) -> list: """根据分数和偏好推荐“冲-稳-保”三个梯度的院校""" 结合往年录取位次、专业热度、地域倾向综合推荐 return [ {"tier": "冲刺", "school": "XX大学", "probability": "30%"}, {"tier": "稳妥", "school": "YY大学", "probability": "70%"}, {"tier": "保底", "school": "ZZ学院", "probability": "95%"} ]
华为云也基于DeepSeek大模型开发了高考志愿推荐系统,结合学生成绩、专业偏好与地域倾向智能生成志愿方案-51。这些案例充分说明,Agent技术在垂直场景中的应用正在加速落地。
七、底层原理深挖:Agent技术依赖哪些基础能力?
Agent之所以能实现自主决策和工具调用,底层依赖以下几个关键技术:
1. Function Calling(函数调用)
这是Agent能够“调用工具”的核心机制。LLM经过专门微调后,不仅能够生成文本,还能输出结构化的工具调用指令(如JSON格式的 {“tool”: “weather_api”, “params”: {“city”: “北京”}})。OpenAI在2023年6月首次在GPT-4中引入此能力,此后各大模型厂商纷纷跟进-。
2. 向量数据库与RAG
Agent的长期记忆通常借助向量数据库(如Chroma、Pinecone、Weaviate)实现。用户的对话历史、偏好信息被转化为向量存储,需要时通过相似度检索召回。Pinecone等向量数据库在过去一年平均降价60%,大大降低了Agent的落地门槛-11。
3. 模型上下文协议(MCP)
随着Agent需要调用的工具数量激增,如何标准化工具与模型的连接成为新问题。MCP(Model Context Protocol)应运而生,被称为AI时代的“USB-C”接口,将数据库schema、API描述、用户历史对话统一序列化为标准格式,成为连接模型与数据源、工具的标准接口-2-11。
4. 多智能体协作(Multi-Agent System)
面对需要多领域协同的复杂企业任务,单一Agent往往力不从心。多智能体系统(MAS)通过将任务拆解并交由不同专长的Agent协作完成,实现“1+1>2”的集体智能-1。2025年,业界已形成层级式、平等式与混合式三类成熟架构,主流框架如AutoGen、CrewAI均支持多智能体协作-1。
八、高频面试题与参考答案
以下精选5道AI Agent方向的高频面试题,均来自2025-2026年大厂真实面试场景。
Q1:LLM和Agent有什么区别?
参考答案(踩分点:定义对比 + 能力差异 + 一句话总结):
LLM(Large Language Model)是一个概率文本生成模型,输入文本输出文本,本身不具备目标意识和执行能力。Agent是以LLM为决策核心,叠加了感知、规划、记忆、行动四个模块的自主系统。简单说:LLM是大脑,Agent是大脑+手脚+工具+目标的完整人-35。
Q2:Agent和Workflow有什么区别?
参考答案(踩分点:确定性 vs 自主性):
Workflow是预设的确定性路径,每一步做什么是代码写死的,适合流程固定的批量任务。Agent具备动态决策能力,能根据中间结果调整下一步计划。比如处理退款申请:Workflow按“检查订单→审核→打款”固定流程走;Agent会先判断订单类型,若金额超过阈值自动转人工,遇到异常自行重试或换方案。Workflow执行路径,Agent生成路径。
Q3:请解释ReAct框架的工作原理。
参考答案(踩分点:三要素 + 循环过程 + 优势):
ReAct(Reasoning + Acting)通过交替执行 “思考→行动→观察” 的循环来驱动Agent。思考阶段LLM分析当前状态并规划下一步;行动阶段调用具体工具;观察阶段获取执行结果并作为下一轮思考的输入。优势是每一步决策都基于实际结果,能有效减少LLM幻觉,提升复杂任务的成功率-61-42。
Q4:Function Calling是如何让Agent调用工具的?
参考答案(踩分点:微调原理 + 结构化输出 + 执行流程):
Function Calling是通过对LLM进行专门微调实现的。微调后的LLM不仅生成自然语言,还能输出结构化的工具调用指令(如JSON格式 {“name”: “weather_api”, “parameters”: {“city”: “北京”}})。开发者在Prompt中描述工具名称、参数类型和描述,LLM判断需要调用时输出结构化指令,由AgentExecutor解析并执行对应函数,再将结果返回给LLM生成最终回复--42。
Q5:多智能体协作有哪些常见架构?分别适合什么场景?
参考答案(踩分点:三类架构 + 场景匹配):
多智能体协作主要有三类架构:层级式(一个主Agent分解任务,多个子Agent执行,适合客服系统)、平等式(多个Agent平等协商、相互协作,适合科研模拟)、混合式(二者结合,适合复杂企业应用)。主流框架中,AutoGen擅长多Agent协作,CrewAI强调角色分工,LangChain侧重模块化开发-69-1。
九、结尾总结
回顾全文核心知识点:
| 知识点 | 核心结论 |
|---|---|
| 为什么需要Agent | 纯LLM只能“说话”,不能“做事”;Agent让AI具备自主行动能力 |
| Agent是什么 | Agent = LLM(大脑) + 感知 + 规划 + 记忆 + 行动 |
| LLM vs Workflow vs Agent | LLM提供认知能力,Workflow提供确定性路径,Agent是自主决策系统 |
| ReAct框架 | 思考→行动→观察的循环,是驱动Agent工作的核心模式 |
| 底层技术 | Function Calling + 向量数据库 + MCP协议 + 多智能体协作 |
| 高频考点 | LLM与Agent区别、ReAct原理、Function Calling机制、多智能体架构 |
学习建议:掌握Agent技术的最佳路径是“概念理解 → 代码实践 → 原理深挖 → 面试准备”四步走。建议先从本文的代码示例入手,在本地跑通一个能调用天气API的Agent,再逐步加入记忆模块和多工具协作,最后结合面试题查漏补缺。
预告:下一篇将深入讲解 “如何用LangGraph构建有状态的复杂Agent工作流” ,涵盖状态管理、条件分支、错误恢复等工程化实践,欢迎持续关注。